Каталог
Программное обеспечение
1016 тов.
Вид:
- Выбрано: 0Тип ПО
- Выбрано: 0Применение
- Выбрано: 0Компания
- Выбрано: 0Производство
- Выбрано: 0Дополнительно
Вид:
1016 тов.

Triafly
Платформа обеспечивает решение следующих задач:
- Сбор и консолидацию данных с иерархической организационной структуры в единое хранилище данных.
- Загрузку данных в хранилище из внешних информационных систем и внешних файлов.
- Систематизацию и хранение данных в виде массивов показателей с набором аналитических признаков.
- Конструирование форм представления данных.
- Вычисления на основе алгоритмов агрегирования и формул расчета.
- Анализ данных.
- Визуализацию на аналитических панелях (дашбордах): таблицах, графиках, картах.
- Подготовку и выпуск регламентированной отчетности.
- Выгрузку данных во внешние файлы и информационные системы.
Использование программно-технологической платформы Триафлай (ПТП Триафлай) позволяет повысить скорость и эффективность внедрения ИАС, а также модифицировать систему в ходе эксплуатации без привлечения разработчиков, средствами пользовательского интерфейса.
Доверенная среда
Москва
Произведено в: Москва
Renga - BIM-система для архитектора
Работа в BIM-системе Renga основана на 2-х основных принципах – проектирование в 3D-пространстве (для быстрой и наглядной работы) и простой контекстно-ориентированный интерфейс (для удобного и простого взаимодействия с 3D-моделью).
Архитектор создает своё здание на 3D-виде, используя для моделирования объектные инструменты (стены, балки, окна и т.д.). В любой момент можно переключиться на план и там продолжить создание 3D-модели.
Многие профессионалы оценили такой подход к проектированию и признали, что скорость работы в Renga выше по сравнению с другими программами.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург
Renga - BIM-система для инженера по водоснабжению и водоотведению
В Renga можно создавать информационные модели внутренних систем водоснабжения и водоотведения зданий и сооружений различного назначения. Инструменты Renga позволяют максимально автоматизировать действия инженера в процессе прокладки трасс водопровода и канализации, при наполнении модели инженерными данными по соответствующим разделам и получении чертежной документации.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург
Renga Standard - BIM-система для малого бизнеса
от
50 000 ₽
Редакция Renga Standard отлично подойдет организациям, занимающимся малоэтажным коммерческим проектированием, а также индивидуальным предпринимателям и фрилансерам, преимущественно проектирующим ИЖС (Индивидуальное жилое строительство).
Renga Standard помогает архитектору создавать концептуальный облик здания, быстро менять его в зависимости от пожеланий заказчика. Проработка интерьера и экстерьера дома в 3D дает возможность архитектору принимать правильные объемно-планировочные решения и безошибочно считать материалы по проекту.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург
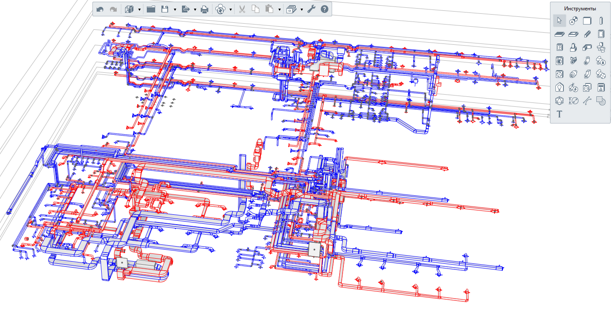
Renga - BIM-система для инженера по вентиляции
В Renga можно создавать информационные модели вентиляционных систем зданий и сооружений различного назначения. Инструменты Renga позволяют максимально автоматизировать действия инженера в процессе прокладки трасс приточных и вытяжных воздуховодов, при наполнении модели инженерными данными по соответствующему разделу и получении чертежной документации.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург

Renga - BIM-система для конструктора
Для разработки ж/б конструкций в Renga предусмотрены мощные инструменты для армирования объектов в 3D. Функция автоматического армирования существенно ускорит процесс раскладки арматуры в монолитных ж/б элементах и позволит быстро и легко получить чертежи заармированных конструкций. Помимо армирования объектов в программе предусмотрено автоматическое усиление арматурными стержнями отверстий и проемов в перекрытиях и стенах. Причем усиление привязано к проему/отверстию и перемещается вместе с ним.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург
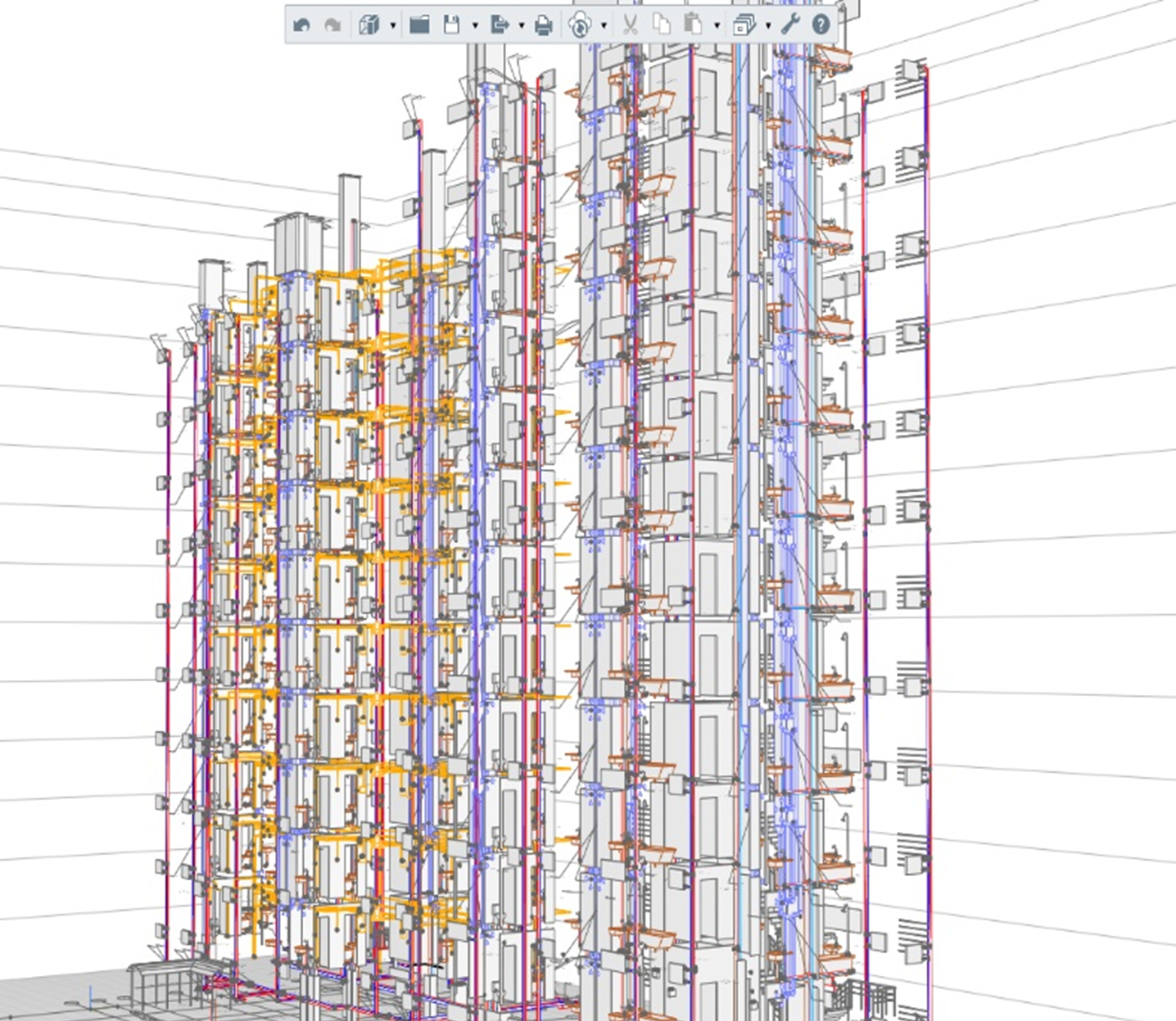
Renga Professional - BIM-система для среднего и крупного бизнеса
от
80 000 ₽
Редакция Renga Professional идеально подойдет средним и крупным проектным компаниям, корпорациям, холдингам, проектирующим здания и сооружения, а также индивидуальным пользователям и небольшим проектным коллективам, участвующим соисполнителями масштабных проектов, в которых необходима совместная работа над проектом.
Renga Professional помогает архитектору создать архитектурный облик здания, быстро менять его в зависимости от пожеланий заказчика. Проработка интерьера и экстерьера здания в 3D дает возможность архитектору принять правильные объемно-планировочные решения, определиться с составом конструкций и отделки, выполнить квартирографию и безошибочно посчитать материалы по проекту. Назначенные текстуры на архитектурные элементы помогают визуализировать здание, а в случае необходимости ускоряют процесс подготовки к получению фотореалистичных иллюстраций.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург

Pharm Frame
PharmFrame - инновационная IT-компания, разрабатывающая программные решения в области управления здравоохранением и Medtech. Команда специалистов высочайшего уровня вывела на рынок РФ несколько успешных продуктов, одним из которых является новаторский метод оценки закупок лекарственных препаратов, основанный на принципах доказательной медицины, являющемся уникальной системой подсчёта рейтинга каждого зарегистрированного в РФ лекарственного препарата на основе Метаанализа, РКИ с наиболее котируемых международных источников данных.
Доказательная медицина — подход, при котором решения об эффективности и безопасности лекарственных препаратов принимаются основываясь на результатах клинических исследований.
Врач, использующий принципы доказательной медицины в повседневной клинической практике, принимает решения, основываясь не на личном опыте или опыте коллег; врач назначет пациенту только те препараты, которые были проверены клиническими исследованиями, то есть доказана их эффективность.
Доказательная медицина — наиболее совершенный на сегодняшний день метод клинической практики, применяющийся во всех развитых странах.
Замена на препараты с более высоким уровнем доказательности осуществляется по группам анатомо-терапевтически-химической (АТХ) классификации ВОЗ.
Замена на препараты с более высоким уровнем доказательности осуществляется по терапевтическим группам Российских клинических рекомендаций.
ФармФрейм
Москва
Произведено в: Москва
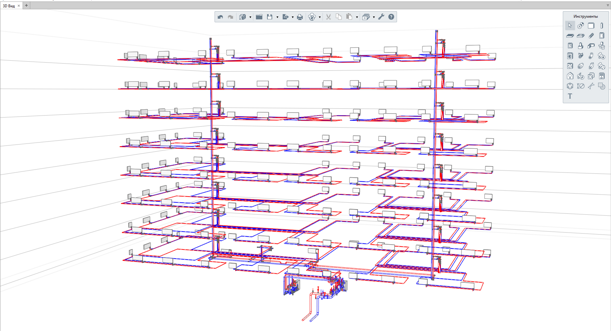
Renga - BIM-система для инженера по отоплению
В Renga можно создавать информационные модели систем отопления и сетей индивидуальных тепловых пунктов (ИТП) зданий и сооружений различного назначения. Инструменты Renga позволяют максимально автоматизировать действия инженера в процессе прокладки трасс подающих и обратных трубопроводов, при наполнении модели инженерными данными по соответствующим разделам и получении чертежной документации.
Ренга Софтвэа
Санкт-Петербург
Произведено в: Санкт-Петербург

NextGIS QGIS
Удобный русифицированный установщик с полностью переработанным набором пакетов
Набор последних версий расширений, разработанных нами и настроенных «из коробки» (NextGIS Connect, QuickMapServices, Identify+)
Интеграция с nextgis.com
Последняя версия русскоязычной документации
NGQ Rosreestr Tools – модуль для работы с данными Росреестра/ЕГРН
Territory Plan Styler – модуль для работы с данными территориального планирования
NextGIS QGIS предоставляет пользователю возможность добавлять:
• Векторные данные.
• Растровые данные.
• Использовать тайловые подложки из интернета.
• Добавлять растры по протоколу WMS и TMS.
• Работать по протоколу WFS.
• Добавлять слои из Веб-ГИС NextGIS Web.
• Предоставляет возможность пользователю добавлять собственные данные.
Некстгис
Москва
Произведено в: Москва

NextGIS Web
Программное обеспечение NextGIS Web представляет собой картографическое веб-приложение.
NextGIS Web позволяет:
создавать и отображать карты и использовать их как геопорталы;
выполнять навигацию по картам (увеличение, уменьшение, перемещение);
управлять наполнением через
веб-интерфейс;
подключать векторные (ESRI Shape, PostGIS, GeoPackage, Mapinfo TAB, MIF/MID и др.) и растровые данные;
использовать стандартные OGC протоколы (WMS, WFS-T, TMS);
гибко настраивать права доступа к слоям, группам слоёв, картам;
взаимодействовать с другими программами посредством API.
Некстгис
Москва
Произведено в: Москва

NextGIS Mobile
ГИС NextGIS Mobile позволяет:
• отображать карту в виде набора слоев;
• выполнять навигацию по карте (увеличение, уменьшение, перемещение);
• добавлять векторные данные из формата GeoJSON;
• добавлять растровые данные в виде тайлового кэша;
• подключать онлайн источник тайлов (XYZ и TMS);
• подключать растровые и векторные слои из nextgis.com1 и NextGIS Web2;
• создавать и модифицировать векторные геоданные (геометрии и атрибуты);
• просматривать атрибуты выбранной геометрии через диалог идентификации;
• модифицировать атрибуты векторного слоя при помощи настраиваемых
форм ввода;
• делиться векторными геоданными с использованием стандартных инструментов Android;
• записывать треки и управлять их отображением, а также удалять выбранные треки или все треки;
• отображать координаты, скорость, высоту устройства на карте, источник географических координат, количество спутников, используемых
для фиксирования местоположения (в случае GPS);
• накапливать и передавать в фоновом режиме по сети Интернет (при наличии подключения) в nextgis.com3 или NextGIS Web4 созданные и/или
измененные геоданные из векторных слоев.
Некстгис
Москва
Произведено в: Москва