Каталог
Вернуться к результатам поиска
RCO Fact Extractor SDK

Вернуться к результатам поиска
RCO Fact Extractor SDK
Библиотека производит лингвистический разбор текста с учетом грамматики и семантики языка и предоставляет программный интерфейс для считывания результатов разбора и использования другими программами (напр., для визуализации полученных данных, построения отчетов и таблиц, организации поиска по объектам и т.д.).
Результатом анализа текста являются выделенные из текста сущности – наименования организаций, персон, географические объекты, различные символьно-цифровые конструкции (такие как номера автомобилей или полисов страхования, адреса), классы сущностей; сеть синтактико-семантических отношений между сущностями текста; структуры данных, описывающие упомянутые в тексте события и факты.
Библиотека универсальна: ее можно настроить на работу с разными предметными областями и даже с разными языками. Всевозможные надстройки над базовой библиотекой позволяют решать совершенно разные задачи: от нахождения информационных дублей (плагиата) и построения смыслового портрета документа, до обезличивания персональных данных в текстах или преобразования поисковых запросов.
Характеристики
Библиотека обрабатывает примерно 40-200 Мбайт «чистого» текста в час. Под «чистым» текстом понимается документ, очищенный от разметки и служебной информации.
Анализ текста состоит из 8ми последовательных ступеней. На каждом этапе задействованы специальные словари, описания объектов и правила, составленные лингвистами для максимально полного и точного извлечения информации в соответствии с заданной задачей и форматами текстов.
Результатом анализа текста являются выделенные из текста сущности – наименования организаций, персон, географические объекты, различные символьно-цифровые конструкции (такие как номера автомобилей или полисов страхования, адреса), классы сущностей; сеть синтактико-семантических отношений между сущностями текста; структуры данных, описывающие упомянутые в тексте события и факты.
Библиотека универсальна: ее можно настроить на работу с разными предметными областями и даже с разными языками. Всевозможные надстройки над базовой библиотекой позволяют решать совершенно разные задачи: от нахождения информационных дублей (плагиата) и построения смыслового портрета документа, до обезличивания персональных данных в текстах или преобразования поисковых запросов.
Характеристики
Библиотека обрабатывает примерно 40-200 Мбайт «чистого» текста в час. Под «чистым» текстом понимается документ, очищенный от разметки и служебной информации.
Анализ текста состоит из 8ми последовательных ступеней. На каждом этапе задействованы специальные словари, описания объектов и правила, составленные лингвистами для максимально полного и точного извлечения информации в соответствии с заданной задачей и форматами текстов.

3i Search Platform
3i Search Platform имеет распределенную архитектуру сбора, индексации данных и обработки запросов. Система сбора данных реализована в виде коннекторов к различным источникам данных, например, к файловой системе или Интернет. 3i Search Platform обойдет внутренние и внешние источники данных, объединит их в единое информационное пространство и предоставит доступ через Web-интерфейс. Посредством SOAP-API можно получить доступ к следующим функциям системы:
- поиск по ключевым словам;
- смысловой поиск;
- нечеткий поиск;
- параметрический поиск;
- поиск похожих документов;
- поиск по различным типам полей;
- поиск с использованием усечения (wildcard);
- поиск с учетом синонимов и пользовательских словарей;
- кросс-языковый поиск;
- автоматическое дополнение запросов при поиске;
- проверка правописания запросов;
- анализ статистики по запросам (анализ интересов пользователей);
- классификация документов;
- ведение различных типов классификаторов для совместной работы (пользовательские, групповые, общие);
- кластеризация документов;
- построение карты связей для кластеров;
- динамическая кластеризация результатов поиска;
- ведение пользовательских агентов для мониторинга данных и уведомлений;
- смысловое аннотирование.
Коннекторы: файловая система, Интернет, POP3/IMAP, Fetch API.
Типы файлов: более 200 различных форматов, среди них XML, HTML, PDF, файлы Microsoft Office и многие другие. Для XML и HTML имеются гибкие настройки.
3i Search Platform поддерживает лингвистическую обработку документов на следующих языках: английский, арабский, иврит, итальянский, испанский, китайский (трад.), китайский (упр.), корейский, немецкий, польский, португальский, русский, турецкий, французский, японский. Также для указанного списка доступно автоматическое определение языка. Список поддерживаемых языков пополняется.
Скоростные характеристики на современных процессорах семейства Intel Xeon:
- индексация на одном ядре со скоростью более 4 MB/s (32 Mbps);
- выполнение более 50 простых запросов в секунду.
ДСС Лаб
Москва
Произведено в: Москва

3i Gender ID SDK
Технология идентификации пола диктора по голосу основана на моделях из смесей гауссовых распределений.
Точность идентификации
- вероятность ошибки принять мужчину за женщину: 0,0096;
- вероятность ошибки принять женщину за мужчину: 0,0357.
Средний уровень ошибок при равном количестве мужчин и женщин оценивался на речевой базе, объёмом более двух тысяч фонограмм и составил 1,63%.
Тип обрабатываемого сигнала:
WAV-файлы, буфер отсчётов;
частота дискретизации 8 кГц;
разрядность квантования 8 или 16-бит;
тип кодирования: A-закон, m-закон или PCM.
Требования к качеству речевого сигнала - отношение сигнал/шум не менее 7 дБ.
SDK реализован в виде DLL-библиотеки, написанной на языке С++, позволяющей потокобезопасное встраивание функций автоматического определения пола в произвольные Windows-приложения.
ДСС Лаб
Москва
Произведено в: Москва

PROMT Neural Translation Server для Linux
PROMT Neural Translation Server подходит для перевода документов и деловой переписки на предприятиях и в организациях, осуществляющих закупки по 223-ФЗ и владеющих критически важной инфраструктурой (КИИ):
- Не требует подключения к интернету. Устанавливается в локальную сеть компании или предприятия на сервер под управлением ОС Linuх. Все функции программы работают непосредственно в локальной сети, это касается и сервера, и данных.
- Имеет сертификаты совместимости c такими российскими ОС, как Astra Linux, РЕД ОС, Alt Linux и другими. PNTS внесен в Реестр российского ПО (номер записи № 15703).
PROMT Neural Translation Server позволяет любому количеству пользователей переводить тексты и документы без ограничений по объему.
PROMT Neural Translation Server является частью экосистемы PROMT. Вы всегда можете дополнить его другими компонентами экосистемы, чтобы оптимизировать работу штатного отдела перевода, библиотечной службы и т.д. Повысить качество машинного перевода можно за счет обучения нейронных моделей.
Сроки выполнения переводческих проектов сокращаются за счет: применения нейросетевых технологий, перевода документов популярных форматов с сохранением форматирования.
Поддержка работы с китайским, немецким, французским, арабским и другими европейскими и азиатскими языками. Доступно 50+ языков в любых комбинациях.
Высокое стартовое качество перевода и возможность тренировки нейронных моделей на ранее переведенных данных.
Установка в локальной сети компании, что гарантирует полный контроль над данными и безопасную работу с корпоративной информацией.
Промт
Санкт-Петербург
Произведено в: Санкт-Петербург
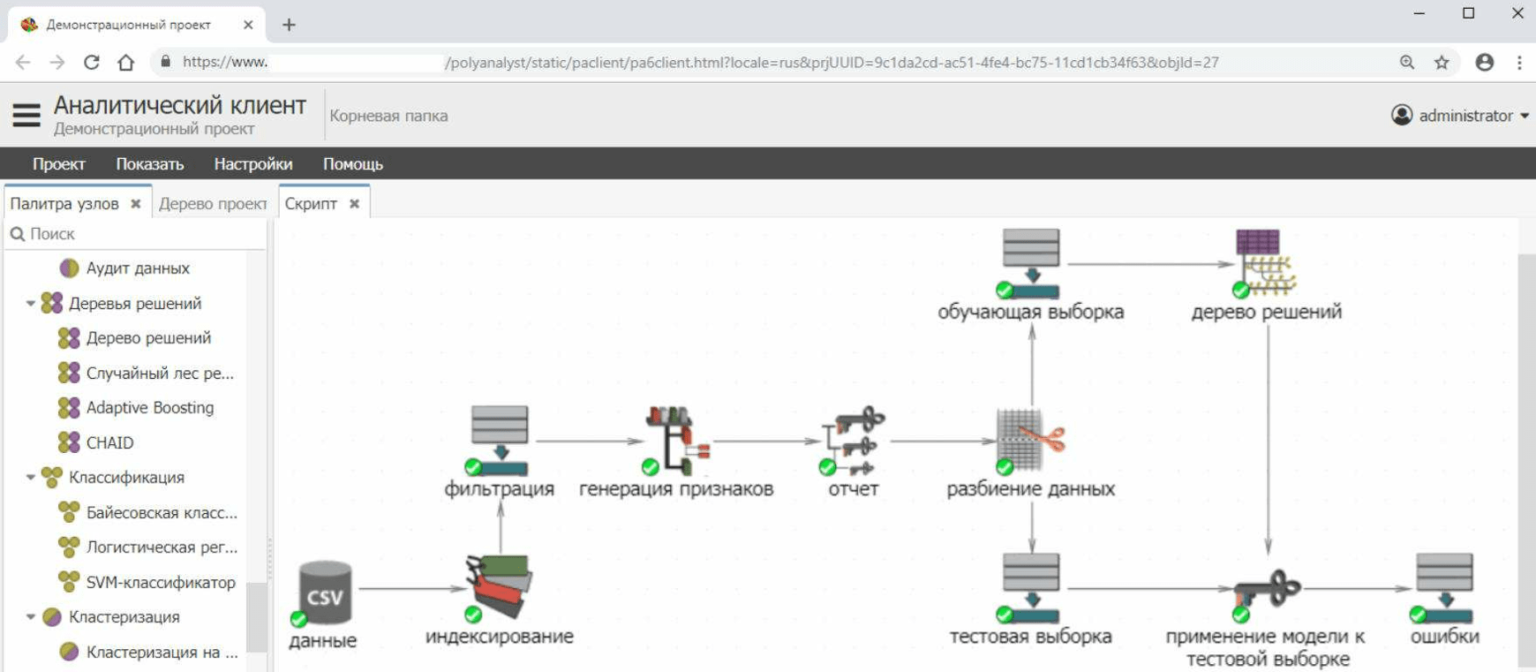
PolyAnalyst Data mining & Machine learning
PolyAnalyst предоставляет широкий выбор алгоритмов машинного обучения и статистической обработки для анализа структурированных данных, таких как числа, строки и даты. Система позволяет решать задачи классификации, кластеризации, предсказания численных значений, выявлять типичные паттерны и аномалии, и строить предсказательные модели на основе анализа временных рядов и сетевых структур.
PolyAnalyst может производить чистку и обогащение данных, используя алгоритмы нечеткого сравнения разных представлений объектов. Построенные системой предсказательные модели позволяют извлекать полезные знания, скрытые в анализируемых сырых данных, и применять эти знания для принятия эффективных управленческих и бизнес-решений.
PolyAnalyst содержит более тридцати современных инструментов интеллектуального анализа, позволяющих решать подавляющее число прикладных задач. Также в PolyAnalyst возможно использовать высокоуровневые языки программирования Python и R для выполнения специальных операций с данными.
- Прогнозирование
- Регрессионный анализ
- Анализ статистических распределений
- Кластеризация
- Анализ покупательских корзин
- Деревья решений
- Анализ временных рядов
- Классификация
- Анализ связей
- Разрешение сущностей.
Произведено в: Москва

ПМ ЭОС
Интеллектуальный программный модуль оценки эмоционального состояния диктора для поддержки принятия решений в контакт-центрах, на основе технологий искусственного интеллекта по интерпретируемой обработки данных и распознаванию речи (ПМ ЭОС) предназначен для обеспечения автоматической оценки эмоционального состояния диктора по акустическим признакам звукового сигнала, содержащего речевое сообщение; автоматического распознавания эмоции по расшифровке входного речевого сообщения и поддержки интегральной оценки эмоции по акустическим признакам и текстовым признакам речевого сообщения.
ПМ ЭОС состоит из одного модуля 3i-speech-service и реализовано в виде серверного приложения, запускаемого в среде Docker.
ДСС Лаб
Москва
Произведено в: Москва

RCO Address Parser
Для адресов РФ реализованы сопоставление с классификатором ФИАС, представление строки адреса в унифицированном виде, выдача списка подсказок-вариантов для продолжения адреса. Также поддерживаются разбор мест рождения СССР. Входными данными является текстовая строка с адресом или набор полей с адресными элементами, возможна также пакетная обработка адресов.
RCO Address Parser 3.0 реализован в виде сервиса с поддержкой протокола SOAP. Для работы не требуется СУБД. Но если пользовательское приложение работает с СУБД Oracle, то оно может использовать дополнительные пакеты, входящие в состав поставки, упрощающие обмен данными c RCO Address Parser 3.0.
Основные виды ошибок/опечаток, устраняемых во входных данных:
Использование схожих по написанию латинских букв вместо кириллических;
Опечатки («ул Перера» исправит на «ул Перерва»);
Неполнота задания адреса (при условии уникальности заданных элементов, например, адрес «ул Xоламская, 31» преобразует в «индекс 361823, респ Кабардино-Балкарская, р-н Черекский, с Герпегеж, ул Холамская, дом 31»);
Преобразование римских цифр в арабские;
Использование старых названий городов и улиц («Арзамас-16, Репина, д.1, кв. 34» преобразует в «индекс 607188, обл Нижегородская, г Саров, ул Репина, дом 1, кв. 34»);
Автозамена часто встречающихся устойчивых сокращений («проф.» вместо «профессора», «ак.» вместо «академика» и т.д.).
Восстанавливаемая адресная информация:
Почтовый индекс;
Код ФИАС;
Код КЛАДР;
Код ОКАТО;
Код ОКСМ;
Пропущенные элементы адреса (область, район и т.п.).
Для устранения неточностей, порой возникающих при разборе адреса, программа генерирует множество гипотез и выбирает наилучшую.
Скорость обработки адресов – порядка 10/сек. на одном процессорном ядре.
Эр Си о
Москва
Произведено в: Москва

RCO News Clustering Engine
Агрегатор новостной ленты использует алгоритмы разбора текста, взаимного взвешивания документов, кластеризации документов. При построении кластеров Агрегатор на каждой итерации рассматривает временной интервал, называемый окном кластеризации. Итерации повторяются со сдвигом окна кластеризации на заданный временной отрезок, называемый шагом кластеризации.
Входной информацией агрегатора являются документы новостной ленты, хранящиеся в базе данных новостей заданного формата. Агрегатор новостной ленты сохраняет результат кластеризации документов в базе данных новостей в специально разработанных таблицах. Результатом кластеризации является набор кластеров. Каждый кластер имеет набор документов, собственно образующих кластер, и набор терминов, характеризующих кластер. Указанные документы и термины имеют свой вес в кластере.
Помимо штатного режима, в котором происходит обработка новых документов, Агрегатор новостной ленты имеет также ретроспективный режим, в котором за явно указанный интервал проводится кластеризация документов с заданными окном и шагом кластеризации. В базе данных сохраняются результаты всех итераций кластеризации.
Внутренняя структура агрегатора допускает достаточно легкую замену одного или нескольких алгоритмов агрегатора на этапе компиляции и сборки ПО.
Эр Си о
Москва
Произведено в: Москва
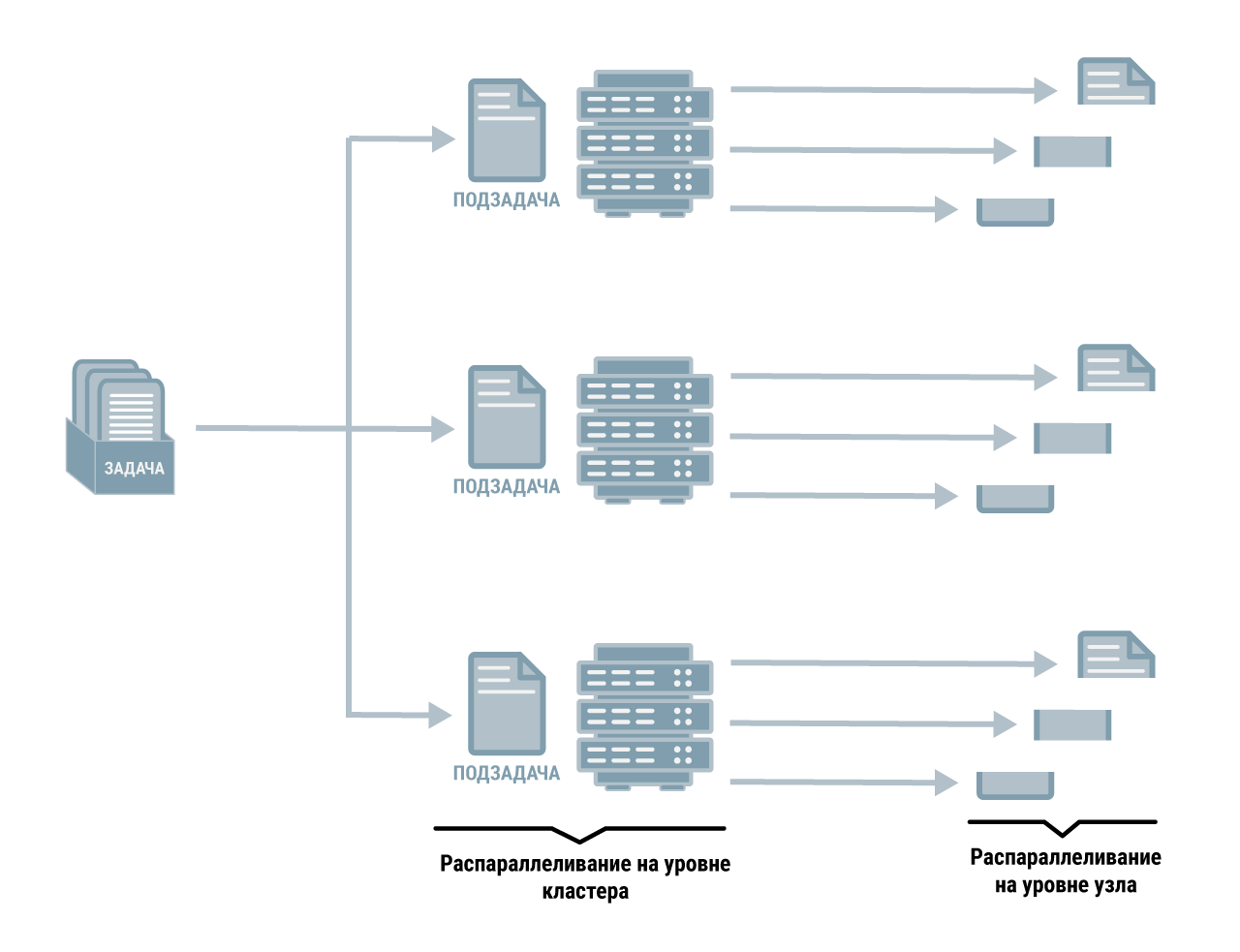
PolyAnalyst GRID
Система аналитики больших данных PolyAnalyst GRID выполняет распределенное хранение и анализ данных на совокупности серверов (узлов кластера), работа которых координируется сервисом базы данных — PolyAnalyst Database Server. Отдельные серверы узлов кластера могут работать как на физических, так и на виртуальных машинах с ОС Linux или MS Windows.
Производительность системы аналитики больших данных (Big Data Analytics)
- Аналитические алгоритмы PolyAnalyst GRID допускают параллельные вычисления, используют все процессорные ядра на вычислительном сервере кластера.
- Аналитические алгоритмы, допускают также распределенные вычисления, дополнительно используют и все вычислительные сервера кластера.
- Производительность алгоритмов системы, которые допускают распределенные вычисления, растет с общим количеством процессорных ядер на всех вычислительных серверах кластера (линейно для большинства алгоритмов).
PolyAnalyst GRID включает инструменты для полного цикла аналитики с большими данными
- Трансформация, очистка и обогащение данных, ETL;
- Статистический анализ и машинное обучение, ML;
- Интеллектуальный анализ текстовых данных, NLP;
Произведено в: Москва

3i Text To Speec
3i TTS API позволяет произвести озвучку любого текста, используя технологию синтеза речи.
Поддерживаемые языки:
Русский язык (Cloud/On-premise)
Доступные голоса:
- Мужской;
- Женский.
ПО состоит из одного модуля 3i-tts-service и реализовано в виде серверного приложения, запускаемого в среде Docker.
ДСС Лаб
Москва
Произведено в: Москва

RCO Deduplicator SDK
Выявление дублей загружаемого документа среди имеющихся в базе данных (БД) необходимо для очистки результатов поиска от лишней информации и, следовательно, упрощения аналитической работы с базой.
Процедура избавления от дубликатов двухэтапная. Первый этап – выявление важных для обнаружения дубликатов характеристик поступившего в систему документа. Второй – поиск дубликатов.
Процедура выявления дубликатов двухэтапная. Первый этап – выявление важных для обнаружения дубликатов характеристик поступившего в систему документа. Второй – собственно поиск дубликатов.
Дубликаты выявляются с использованием следующих условий:
- Хотя бы одна контрольная сумма предложений совпадает (необходимое условие);
- Разница в числе слов документов не превышает заданного значения или отношение длин документов не превосходит определенного значения (необходимое условие);
- Все контрольные суммы предложений совпадают (достаточное условие);
- Контрольные суммы частых слов совпадают (достаточное условие.
! Использование библиотеки RCO Deduplicator возможно лишь при наличии работающей версии программы RCO Fact Extractor !
Эр Си о
Москва
Произведено в: Москва

3i Search Platform 3.x
3i Search Platform 3.x реализует широкий спектр технологий обработки текстовой информации: информационный поиск, классификацию, кластеризацию, аннотирование, выделение сущностей и многих других.
ДСС Лаб
Москва
Произведено в: Москва
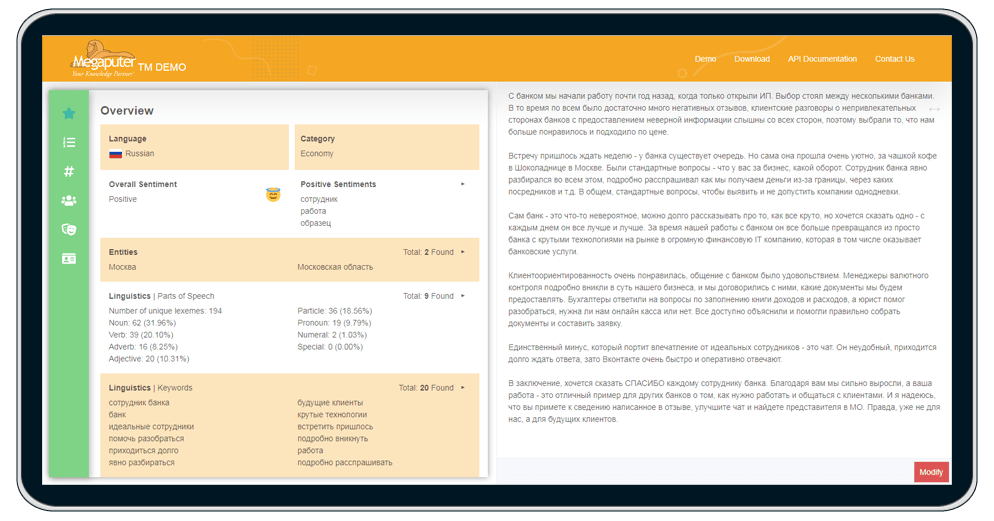
PolyAnalyst Text mining & NLP
PolyAnalyst Text решает весь спектр задач текстового анализа: извлекает факты и отношения из документов, кластеризует и классифицирует тексты, составляет аннотацию, анализирует тональности и многое другое.
Технология text mining позволяет выполнять обработку естественного языка, которая по глубине и точности превосходит результаты аналогичных технологий. Кроме инструментов анализа текста, в систему также входят средства семантического анализа и алгоритмы машинного обучения. Вы сможете анализировать текстовые документы и отзывы в разных форматах и на разных языках, а также документы, содержащие как структурированные, так и неструктурированные данные.
Text mining инструменты решающие все задачи анализа текста:
- Извлечение фактов
- Распознавание сканов
- Классификация
- Обезличивание
- Анализ тональности
- Резюмирование
- Кластеризация
Система интеллектуального анализа текста органично сочетает в себе передовые инструменты обработки естественного языка, средства семантического текстового анализа и алгоритмы машинного обучения, что позволяет пользователям получать результаты высокой точности. Мы предлагаем вам:
- средства для загрузки данных из всех популярных источников и документов разного формата;
- эффективные инструменты Text Mining для очистки и преобразования данных;
- непревзойденную систему интеллектуального анализа текста, включающую в себя:
- инструменты лингвистического (лексического, морфологического и синтаксического) анализа;
- поддержку онтологий и семантических словарей;
- статистические инструменты и алгоритмы машинного обучения.
Произведено в: Москва
Облачная платформа SpaceVM
Облачная платформа SpaceVM - Представляет собой комплексную платформу для развертывания полноценного частного облака в корпоративной среде с необходимыми дополнительными инструментами для автоматизации и оркестрации работы облачных сервисов.
SpaceVM работает на базе серверов стандартной архитектуры x86-64 и позволяет перенести в облако не только веб-сайты, порталы, бизнес-приложения и рабочие станции сотрудников, но и обеспечивает работу телекоммуникационных сервисов, виртуальных маршрутизаторов, межсетевых экранов, почтовых и прокси-серверов.
SpaceVM помогает снизить расходы на ЦОД, повысить время бесперебойной работы систем и приложений, а также значительно упростить работу ИТ-отдела в ЦОД.
Облачная платформа SpaceVM – полнофункциональный российский аналог систем серверной виртуализации иностранного производства: VMware, Microsoft. Построение ИТ-инфраструктуры предприятия с использованием платформы SpaceVM повзолит предприятию обеспечить санкционную устойчивость и технологический суверенитет.
SpaceVM предоставляет свободу выбора при построении комплексных проектов, расширяя возможности системы за счет использования открытых API-интерфейсов, реализующих взаимодействие с решениями ведущих российских поставщиков технологий, объединенных в глобальную экосистему.
Возможности SpaceVM:
- Гипервизор первого типа
- Поддержка широкого спектра гостевых операционных систем на виртуальных машинах, в том числе различные выпуски Linux и Windows ОС.
- Возможность работы на распространенных серверных платформах иностранного и отечественного производства (из реестра МПТ)
- Поддержка функций высокой доступности (High Availability) и динамического перераспределения ресурсов (DRS)
- Поддержка внешних СХД
- Обеспечение живой миграции VM между хостами и хранилищами кластера
- Поддержка виртуализации графических ресурсов (vGPU).
Даком М
Москва
Произведено в: Москва

PROMT Neural Translation Server
PROMT Neural Training Аddon позволяет заказчикам самостоятельно создавать специализированные модели перевода на своих данных. При использовании PROMT Neural Training Addon любая используемая информация защищена от утечки, а количество тренировок неограниченно.
ТРЕБОВАНИЯ К ДАННЫМ
✔ Данные в формате tmx, UTF-8
✔ Рекомендуемый объем от 10 000 сегментов
БЕЗОПАСНОСТЬ И КОНФИДЕНЦИАЛЬНОСТЬ
✔ Работает офлайн
✔ Тренировка на стороне заказчика
✔ Тренировочные данные не доступны третьим лицам
РЕЗУЛЬТАТ
✔ Специализированная модель
✔ Модель подключается в PROMT Neural Translation Server через профиль перевода
✔ Профиль перевода доступен для перевода текста, документа, сайта, в CAT-системе (PROMT Translation Factory, Phrase, Trados Studio).
Промт
Санкт-Петербург
Произведено в: Санкт-Петербург
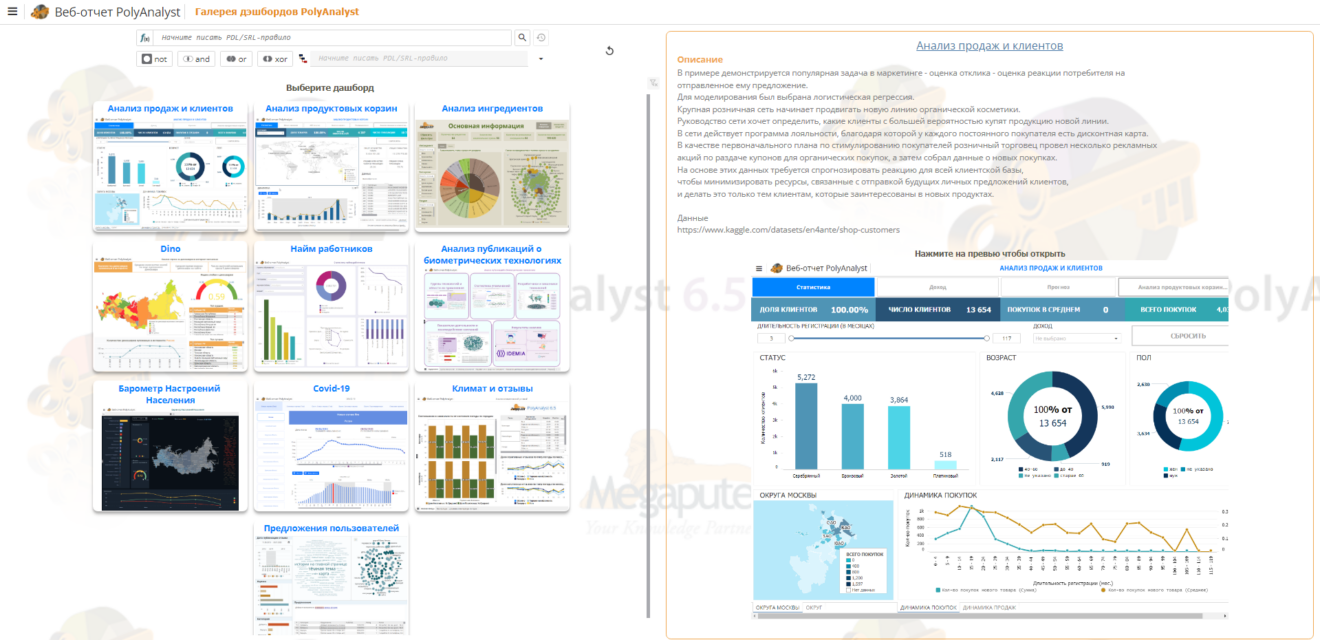
PolyAnalyst Extraction, Transformation, Loading & Business Intelligence
Инструменты ETL и BI для преобразования данных и конструирования веб-отчетов PolyAnalyst ETL & BI предоставляет пользователям средства self-service трансформации данных, а также отображения результатов сложных алгоритмов анализа в виде интерактивных графических отчетов, доступных для понимания неспециалистов.
ДОСТУПНА ВСЯ ПАЛИТРА ETL-ИНСТРУМЕНТОВ:
- Объединение - Аналог SQL JOIN
- Конкатенация - Аналог SQL UNION
- Агрегирование - Аналог SQL GROUP BY
- Разность - Формирование таблицы из записей, имеющихся в одной таблице, но отсутствующих в другой
- Производные колонки - Расчет и вывод новых производных вычисляемых атрибутов, а также построение правил проверки данных
- Условия - Позволяет установить условия для выполнения дочерних узлов, что способствует автоматизации выполнения скрипта
- Фильтрация строк - Фильтрует записи согласно критерию, заданному аналитиком
- Фильтрация данных - Позволяет фильтровать колонки, которые не представляют интереса с точки зрения статистического анализа данных
- Транспонирование - Позволяет переводить данные из строчного представления в колонки. Аналог функции PIVOT
- Выборка - Генерирует из талицы данных случайные выборки записей или выборки, отвечающие определенным условиям
- Редактирование таблицы - Позволяет вручную редактировать данные в исходной таблице
- ABC/XYZ анализ - Позволяет разделить продукты на 3 группы (A, B и C) по критерию привлекательность продукта, или группы X, Y и Z по стабильности продаж
- RFM анализ - Позволяет разделить клиентов на различные сегменты в зависимости от их активности и ценности для компании
- Извлечение и замена терминов
- Уникальные записи
- Модификация колонок
- Сортировка строк
- Дискретизация
- REST - Простой инструмент для отправки запросов GET/POST/PUT/DELETE без написания самих запросов
- Python
Всего более 100 Self-Service инструментов для работы с данными.
ETL & BI инструменты: преимущества использования PolyAnalyst ETL & BI системы для трансформации и анализа больших данных
- Загрузка, трансформация, очистка, обогащение и графическое предоставление данных в одной системе, без необходимости сопряжения различных программных продуктов;
- Создание модели proof of concept бизнес-пользователем за 1 час без привлечения ИТ-специалиста;
- Несколько десятков Low-code инструментов преобразования данных, настраиваемых без программирования;
- Последовательности аналитических процедур легко настраиваются на регулярное автоматизированное выполнение;
- Возможность интеграции кода и моделей, разработанных на языках Python и R;
- Оперативное self-service создание пользовательских отчетов;
- Свыше 30 нативных графических инструментов для построения отчетов, настраиваемых без написания кода;
- Удобный веб-интерфейс для работы в браузере;
- Возможность многомерного представления результатов;
- Гибко настраиваемая ролевая модель, разграничивающая доступ к данным и отчетам;
- Высокая масштабируемость и производительность: поддержка крупных массивов данных и большого количества пользователей;
- Возможность полностью автономной работы системы в закрытом контуре заказчика или публикации отчетов в Интернете с использованием безопасного шифрованного канала доступа.
Произведено в: Москва

3i Speech Detector SDK
В библиотеке реализовано два подхода к сегментации звукового потока.
Первый подход является аналогом VAD – Voice Activity Detection и работает на основе информации об уровне энергии в сигнале.
Второй подход основан на обнаружении в звуковом потоке признаков основного тона (PTD – Pitch Tone Detection). Присутствие в сигнале признаков основного тона, как правило, сигнализирует о наличии речи. Определение основного тона осуществляется при помощи комбинации следующих методов:
- метод частотной селекции;
- метод на основе кепстральных коэффициентов;
- метод на основе классической автокорреляционной функции (ACF – autocorrelation function);
- модифицированный автокорреляционный метод (AMDF - average magnitude difference function based method).
Комбинация четырёх указанных методов обеспечивает высокую надёжность обнаружения речевой составляющей в звуковом потоке даже в сигналах с высоким уровнем помех.
Тип обрабатываемого сигнала:
- WAV-файлы, буфер отсчётов;
- частота дискретизации 8 кГц;
- разрядность квантования 8 или 16-бит;
- тип кодирования: A-закон, m-закон или PCM.
Библиотека реализована в виде DLL-библиотеки, написанной на языке С++, позволяющей потокобезопасное встраивание функций автоматического определения пола в произвольные Windows-приложения.
ДСС Лаб
Москва
Произведено в: Москва