Каталог
Поиск
16 тов.
Вид:
16 тов.

Облачная платформа Базис.Cloud
Функциональные возможности Базис.Cloud:
Технологии оптимизации работы с памятью
Миграция виртуальных машин между хостами с разными процессорами
Автоматизация развертывания серверных узлов
Прямое подключение физических устройств к виртуальным машинам
Интеграция с системами хранения данных
Автоматизация управления питанием неиспользуемых серверных узлов
Изменение настроек виртуальных машин онлайн
Интеграция с виртуальными рабочими столами пользователей
Базис
Москва
Произведено в: Москва
Arenadata Streaming
Высоконагруженные внутренние системы предприятия характеризуются огромными потоками данных, например, миллионами поступающих в минуту сообщений. Чтобы справиться с этим обилием, необходимо осуществлять безостановочный и отказоустойчивый обмен данными между требуемыми компании приложениями. При этом важно, чтобы в процессе не происходило потерь данных. Arenadata Streaming эффективно решает задачи корпоративной шины обмена данными: она способна получать и обрабатывать данные из многочисленных внешних систем, хранить их в течение нужного для бизнеса периода времени и возвращать потребителям с удобной для них нагрузкой.
Аренадата Софтвер
Москва
Произведено в: Москва
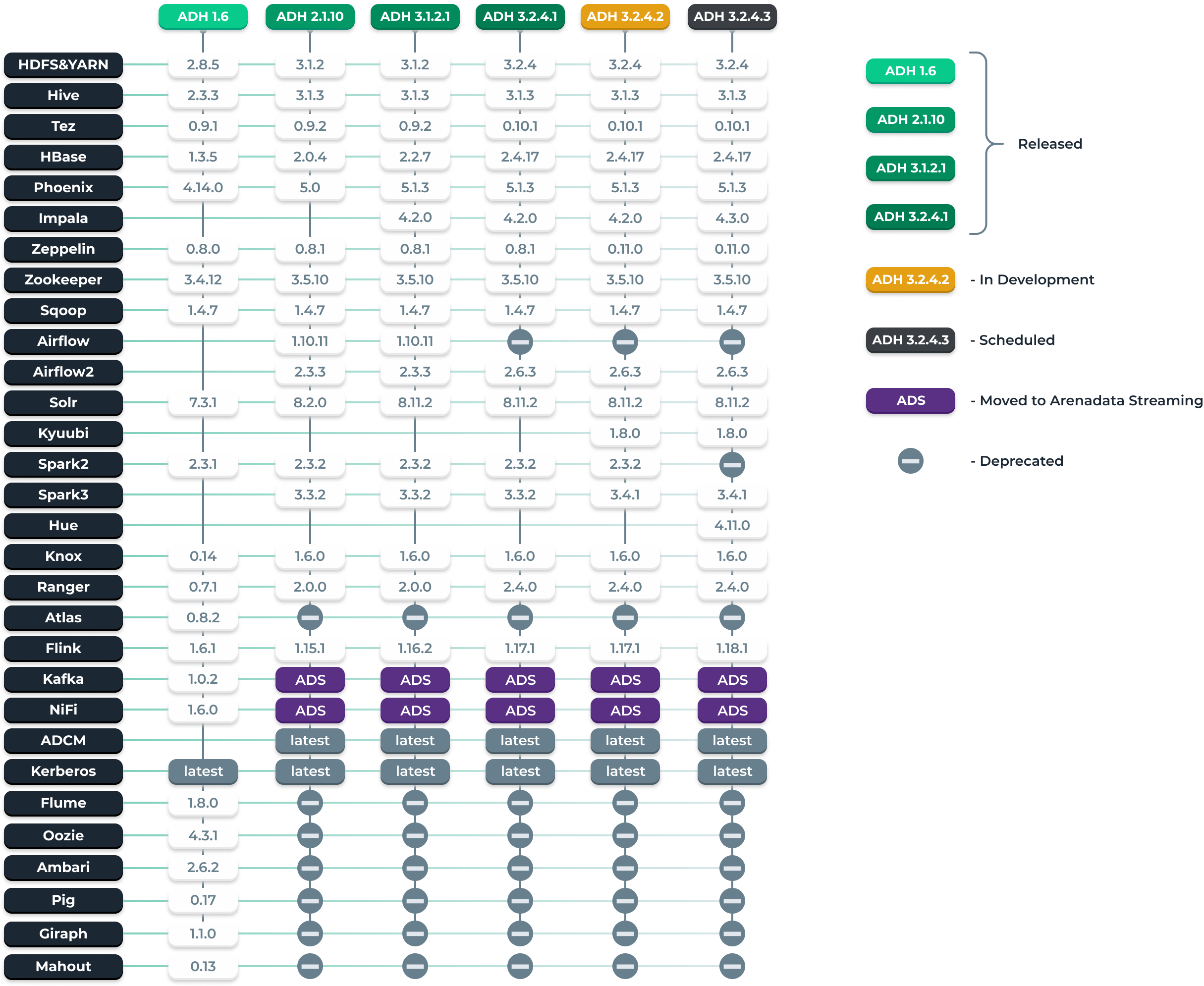
Arenadata Hadoop
Большие данные необходимы компаниям, которые хотят улучшить клиентский сервис, усовершенствовать существующие бизнес-процессы и успешно построить новые, повысить финансовые показатели и опередить соперников в конкурентной борьбе. Чтобы все эти стремления стали частью реальности, неизбежно потребуется надёжный продукт, который позволит хранить, обогащать, обрабатывать поступающую из многочисленных источников информацию. С этой задачей отлично справляется Arenadata Hadoop, который успешно используется ведущими российскими компаниями и госсектором.
Аренадата Софтвер
Москва
Произведено в: Москва
OPC сервер SNMP
Научно-производственная фирма «КРУГ» имеет многолетний опыт создания OPC-серверов для устройств различных производителей. Среди наших разработок OPC-серверы для разнообразных устройств и протоколов, таких как:
Электросчетчики СЕ-102, СЕ-306, «Меркурий-236»
Измерители показателей качества электроэнергии серии «Ресурс-UF2», «Ресурс-ПКЭ», «Ресурс-UF2M (С)»
Приборы пожаротушения (приборы АИСТ и ШУМИЖУ, комплект пожаротушения «СПРУТ-2»)
Протоколы MODBUS RTU/ASCII и MODBUS TCP, SNMP
КРУГ
Пенза
Произведено в: Пенза
Tarantool Graph DB
Российская графово-векторная база данных. Анализируйте связи между данными в реальном времени, используя высокоскоростное хранилище графов и векторов.
Tarantool
Москва
Произведено в: Москва
Tarantool Queue Enterprise
Распределенная in‑memory система очередей сообщений. Позволяет создавать очереди с различной архитектурой в зависимости от потребностей бизнеса.
Tarantool
Москва
Произведено в: Москва
Arenadata QuickMarts
С помощью ADQM вы можете в режиме реального времени генерировать аналитические отчёты разного плана, используя большие объёмы информации, хранящейся в плоских витринах. ADQM многократно быстрее традиционных СУБД.
Мы включили в наш продукт:
Авторизацию пользователей;
Разграничение доступов;
Поддержку High Availability;
Поддержку ORC;
Поддержку интеграции с Kerberos Hadoop.
Помимо этого, ADQM является частью платформы Arenadata Enterprise Data Platform (EDP).
Аренадата Софтвер
Москва
Произведено в: Москва
Информационно-поисковая система "КОНИ-3"
от
1 000 000 ₽
ИПС «КОНИ-З» нацелена на эффективное решение всех поставленных задач по развитию информационного обеспечения Российского коневодства. Разработана единая программно-аппаратная система, обеспечивающая как уже существующие функции, так и новые возможности – центральное хранилище информации, мощный статистический анализ данных, публикация данных во всемирной сети Интернет и использование дополнительных возможностей и масштабирования системы.
Произведено в: Рязань
Система извлечения данных из неструктурированных медицинских записей
Функциональные возможности
Автоматическое извлечение информации из неструктурированных медицинских записей
Автоматический поиск и удаление ошибочных записей и выбросов
Возможность автономного использования продукта, в т.ч. встраиванием в сторонние решения
Извлечение объективных данных, симптомов из жалоб, признаков из врачебных осмотров и протоколов инструментальных исследований, результатов лабораторной диагностики, данных о назначенных лекарствах и т.д.
К-СКАЙ
Петрозаводск
Произведено в: Петрозаводск

Arenadata Postgres (ADPG)
Arenadata Postgres — СУБД для эффективной работы с нагрузкой разного профиля (в первую очередь OLTP — Online Transaction Processing). Arenadata Postgres позволяет работать с различными объёмами данных и поддерживает широкий набор типов данных (в том числе JSON и пользовательские типы) с возможностью гибко программировать механизмы обработки данных.
Аренадата Софтвер
Москва
Произведено в: Москва
Модели машинного обучения в Webiomed
Для нашей системы мы создаем различные модели на основе машинного обучения. Главное – это предиктивная аналитика, которая позволяет системе предсказать возможные события со здоровьем пациента. Но нам также нужны модели извлечения признаков из текстовых записей и модели для выявления подозрений на заболевания
К-СКАЙ
Петрозаводск
Произведено в: Петрозаводск
Базис.Storage Security
Функциональные возможности Базис.Storage Security:
Предоставление доступа к емкости СХД в виде блочных устройств
Мониторинг и поддержание работоспособности СХД
Обеспечение целостности данных
Управление доступом к системе на основе ролевой модели
Регистрация событий безопасности
Сбор и хранение настроек СХД, журнала системных событий, статистической информации
Интерфейс командной строки и веб-интерфейс для управления компонентами СХД.
Базис
Москва
Произведено в: Москва